Wight now we have a partially functional framework with working examples and initial native benchmarking tools. Faster implements a subset of the ideal functional operators for the different dataset types available. Most of them have very low latency:
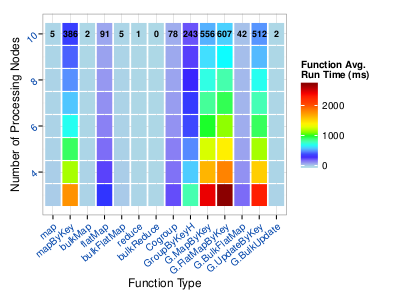
Faster is able to create datasets from disk and from memory, apply several functional programming operators in parallel distributed across multiple machines, collect the result or distributed data, and write on Disk. In the examples directory in de source we have several toy examples and also some algorithms. One of the alforithms is a Pagerank implementation that rendered up to 30x speedup over Spark.
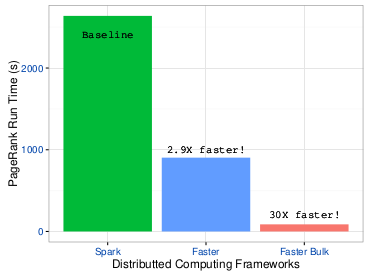
With our performance results we have presented an paper at the 16th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGrid2016).
Faster: a low overhead framework for massive data analysis
Matheus C. Santos, Wagner Meira Jr., Dorgival Guedes and Virgı́lio F. Almeida
CCGrid2016


